主页 > imtoken唯一官网 > 比特币系统发病数量 必读! 未来月薪十万的五把武器(一)
比特币系统发病数量 必读! 未来月薪十万的五把武器(一)
出品 | 区块链训练营(blockchain_camp)
#本文节选自《区块链与产业创新》,文末送纸质书5本!

目前,区块链技术已经从1.0版本过渡到2.0版本,并逐步向3.0版本发展。 新一代区块链技术发展的主要方向集中在基础设施建设上,即区块链底层技术的研发和一些具体应用的落地。 区块链3.0技术发展的目的是提高区块链的整体运行性能,包括通过各种方式提高区块链系统的交易能力、交易速度和系统可扩展性。
在区块链1.0体系中,比特币最具代表性。 在比特币系统中,每个区块的容量为1MB,每10分钟发布一个区块。 按0.25KB的交易计算,平均每秒可以打包1000/0.25/60/10=6.67笔交易。 也就是说,以目前的比特币区块大小,每秒只能承载7笔交易,即7TPS。 以太坊作为区块链2.0系统的代表项目,目前大概可以支持20TPS。
如果与中心化交易系统的处理能力相比,Paypal的处理能力在每秒100笔的数量级,而支付宝在“双十一”期间的处理能力达到了每秒10万笔的数量级。 因此,大众很难想象这样的区块链系统如何应对高频数据调用和存储。
在提升性能的解决方案方面,社区尝试通过区块扩容、隔离见证等一系列技术来提升交易处理能力。
块扩展
对于比特币系统来说,提高系统交易容量的有效途径之一就是区块扩容。 但是,区块的大小会影响整个网络账本同步时间的长短。
以当前比特币系统中单个区块的生成周期为例。 新生成的区块至少需要半分钟才能在网络中广播。 半分钟的广播时间意味着每个验证节点接收新区块的实际顺序是顺序的。 这样的设计不会在块容量有限的情况下暴露出潜在的问题。 这是因为:
假设为了扩展系统,将比特币的区块生成间隔改为半分钟,相当于全网同步所需的时间。 一旦系统将每个区块的生成间隔设置为半分钟,对于高算力的验证节点具有极大的优势。 高算力验证节点可以通过自私挖矿或分叉攻击威胁全网安全。
这里需要对自私挖矿和分叉攻击进行说明,以便读者更直观地了解上述问题的严重性。 通常意义上的自私挖矿或分叉攻击是指在区块链系统网络中,当一个验证节点验证一个新区块时,并不向全网广播,而是继续其验证步骤,直到本地验证的链长于所有链,并一举广播到全网,将本应全网验证的链替换为只在本地验证过的链。
从本质上讲,比特币系统的安全模型将在此时崩溃。 同样,如果区块大小增加 10 倍,全网同步传输所需的时间也会相应增加。 当传输速度与区块生成速度相比不可忽略时,比特币的安全性将大大降低。
在现有的比特币网络中,如果系统生成区块的间隔时间人为设置为10分钟,那么单个区块的容量不能超过4MB。 与目前1MB的区块容量相比,交易速度只能提升4倍,即28TPS。 这种速度提升非常有限。
隔离见证
隔离见证(Segregated Witness,SegWit)是一种在不增加区块容量的情况下,提高系统交易速度的技术尝试。 其设计思路如下。

在比特币系统中,每笔交易数据都包含一个验证签名,约占数据空间的 65%。 为了有效利用这部分数据空间,Segregated Witness技术提出将验证签名移至交易数据的末尾,从而释放原本由验证签名占用的数据空间。 据粗略统计,这一变化可以有效地将原来1MB的块容量增加到1.8MB。
Segregated Witness技术主要解决交易信息被更改的问题。 事实上,这一变化阻止了第三方可扩展性,并使闪电网络等侧链的实施更加容易。 同时,隔离见证技术也增加了比特币系统中简单智能合约的可用性。
然而,这些尝试并没有带来交易处理能力数量级的提升。 因此,在侧链概念的基础上,比特币社区提出了比特币闪电网络(Lightning Network)的解决方案。 闪电网络背靠比特币区块链,实现真正的点对点链下小额支付交易,一定程度上打破了交易中面临的延迟、最终性、容量甚至隐私等问题。
提升以太坊整体性能的思路有两个:第一个是使用侧链技术,类似于比特币的闪电网络项目和Plasma项目,第二个是使用分片技术(Sharding)。
碎片化
1.比特币的UTXO账本模型
介绍分片,首先要从比特币说起。 事实上,所有的区块链都可以抽象为两部分:分类存储和计算。
可以将比特币视为存储数字或账户余额的分布式账本。 它是一个现金交易系统,实际上只有两种状态,即账户余额只有两种状态:已花费的钱和未花费的钱。 这就是比特币的UTXO(Unspent Transaction Output)账本模型,中文翻译过来就是“未花费的输出”。 Transaction在比特币社区通常简称为TX,所以上面的短语简称为UTXO。
那么,记录在比特币区块链账本中的每一笔交易,都包含了一笔交易的输入,也就是资金的来源; 它还包括一些交易输出,即资金的去向。 一般来说,每一笔交易都需要花费至少一个输入并产生一个输出,而产生的输出是“未花费的输出”,即UTXO。 它的特点是简单。
比特币挖矿采用 PoW(Proof of Work)共识机制。 当共识形成后,会有一个临时的分叉,即分叉链,需要6个区块来确认。 确认的方法是选择最长的链,哪个分叉最长就去哪边挖矿。 这是PoW的一个弱点,即达成的共识不是最终共识,需要二次确认才能成为最终共识。 而那些不在最长链上的区块称为孤块(Orphan Block),随后被废弃。
2. 以太坊智能合约
以太坊的本质是一个基于事务的状态机(Transaction-based State Machine),可以看作是一个分布式账本,存储了图灵的完整代码和状态转换操作。 它引入了智能合约,用户可以创建智能合约,并调用智能合约的函数来改变其内部状态。 与比特币的UTXO账本相比,以太坊大大增加了记录大量复杂状态的能力。 这一创新使得以太坊成为了一个状态副本机(State Replica Machine),而这个状态副本机采用了拜占庭容错机制(BFT),从而开启了区块链的智能合约时代。
不同于中本聪的挖矿PoW共识机制,以太坊的挖矿共识机制在PoW的基础上进行了优化,引入了GHOST(Greedy Heaviest Observed Subtree)协议和Uncle Block的概念。
GHOST协议并不认为孤块没有价值,而是奖励发现孤块的矿工。 在以太坊中,孤立块被称为叔块。 GHOST 协议为叔块付费比特币系统发病数量,这会激励矿工在新发现的块中引用叔块。 而引用叔块会使主链变重(基本原则是包含最多的子块)。 在比特币中,最长的链是主链。 在以太坊中,最重的链是主链。 然后,以太坊这些经过优化的确认方式,使得每个节点都可以通过拜占庭算法与其他节点进行一对一的通信,最终的共识是最终共识(Consensus Finality),不需要重新确认。
BFT算法,尤其是PBFT(Practical Byzantine Fault Tolerance,实用拜占庭容错算法)和各种改进的BFT算法涌入区块链。 技术细节很多,但可以归纳为一点:应用了比特币和以太坊的PoW算法(俗称挖矿),优点是便于全球传播。 比如比特币有几千个验证节点,以太坊有20000到30000个验证节点(2018年3月有25000个),但是它的交易处理速度比较慢,比特币7TPS,以太坊20TPS左右。 PBFT算法的应用正好相反。 它的事务处理速度可以比较快。 比如可以做到10000TPS,但是节点数支持的少,很难超过20个。而且,很多都在一个数据中心,甚至可能在数据中心同一个盒子里。
近年来,PoW在提高交易处理速度方面的努力主要体现在PoS(Proof of Stake,权益证明)和DPoS(Delegated Proof of Stake,权益证明)上。 这取决于谁拥有大量的原生虚拟令牌并且时间长。 这种方式大概可以将处理速度提升到几千TPS,比如2000~5000TPS,同时不牺牲全局铺设的优势。
但是,PoS和DPoS也有一定的不足,那就是相对于经过严格理论验证的BFT,PoW经过7年多的实践验证证明是有效的,而PoS还没有经过大规模的检验网络。 从以太坊的发展方向2来看,它的PoS解决方案叫做Casper,考虑实际落地大概需要2年时间。 而且,由于从PoW到PoS的转换会涉及到当前社区利益的分歧,妥协的结果很可能是PoW+PoS的双头并存。 这样的结果会使问题变得更加复杂,并不能解决以太坊的速度短板。
该算法由Miguel Castro和Barbara Liskov于1999年提出,解决了原始拜占庭容错算法效率低的问题,将算法复杂度由指数级降低到多项式级,使得拜占庭容错-容忍算法在实际系统应用中是可行的。 论文发表于1999年操作系统设计与实现国际会议(OSDI99)。这位Barbara Liskov是著名的里氏代换原则(LSP)的提出者,2008年图灵奖获得者。
3. Sharding技术原理
通常,区块链网络的处理速度在很大程度上取决于单个节点的处理速度。 然而,随着越来越多的验证节点加入区块链网络,系统速度和性能并没有简单的提升。 此时,由于节点间点对点通信路径的增加,系统反而会面临网络拥塞的问题。 问题。 例如,如果使用 BFT 共识协议的区块链网络超过 16 个节点,速度就会变得很慢。
分片协议就是为解决这个问题而提出的解决方案。 其核心思想是将网络中的所有节点划分为若干个子组,这些子组通过预定的方法执行所有节点必须处理的工作,从而达到提高系统处理能力的目的。
分片协议规定,为了保持系统的容错性,分片的节点数不能低于一定数量。 例如,考虑到拜占庭容错算法在验证过程中50个和500个节点没有太大区别,系统可以将区块链网络的最小节点数设置为50个。前提是系统采用分片技术,参与区块链网络的节点越多,系统可以切分的片数就越多; 分片越多,意味着区块链网络同时处理智能合约。 数越高。 那么,使用分片技术的区块链系统的速度将得到显着提升。
4. Zilliqa、以太坊和 Moker
a) Zilliqa 分片策略
ZLillia 项目旨在通过分片和独特的共识机制来提高区块链的吞吐量。 在 ZLillia 的设计中,每 600 个节点分配一个网络分片,多个分片组成的并行网络就是分片网络。 这类似于物理学中的并联和串联。 每600个节点放在一个分片中串联,然后不同的分片并联。
考虑到在Zilliqa项目中,系统使用的共识机制是实用拜占庭容错,当系统将每个分片的节点数设置为600时,其速度瓶颈就会凸显。 项目方提出的方案是在每个分片的600个验证节点中选出一个组长,其余599个验证节点都知道组长的身份信息。 因此,原来每个验证节点需要向其他599个验证节点发送验证信息的机制(拜占庭容错的要求)变成了只需要向组长发送验证信息; 组长收到所有验证信息后,通过多重签名记录验证结果。 因此,验证过程中的信息量将大大减少,系统速度将得到提升。
然而,Zilliqa 的解决方案也有其自身的问题。
首先,团队领导者的集中作用是一个弱点。 假设另外 599 个验证节点中有一个被黑客控制,那么这个节点很容易通过 DDoS 攻击(分布式拒绝服务)使分片失效,最终导致系统崩溃。
二、采用拜占庭容错机制的系统并不假设网络中的验证节点事先知道其他节点的身份,但在Zilliqa项目中,由于领导节点身份的特殊性,领导节点需要确认其他599个验证节点的身份才能保证分片的可靠性,显然这样的验证节点区分机制有悖于拜占庭容错机制的初衷。
第三,Zilliqa系统是硬分叉和硬分片的。 也就是说,系统会按照固定的分片原则进行分片,然后将不同的交易分到不同的分片中。 同时,系统必须根据地址进行判断,保证同一个地址到同一个分片。 这不仅增加了系统的复杂性,也增加了交易中潜在的双花风险。

b) 以太坊分片策略
以太坊目前的分片策略是在一个合约处理周期内将网络中的所有节点分成若干部分,然后将合约分配给每个分片。 当合约处理周期结束时,系统会根据实际情况重新分片下一个合约。
这里有几个问题:
c) Moac分片策略
墨客(MOAC)底层采用PoW方式保证数据一致性,其底层母链节点一般称为验证节点(Validation Node,V-Node)。
进行分片处理的节点称为Smart Contract Server(SCS)节点,每个SCS节点通过V-Node连接到母链,使得SCS节点可以通过V-Node获取全局一致的区块信息。 各个SCS之间的通信必须通过V-Node转发信息,以防止SCS受到DDoS攻击,如下图所示。
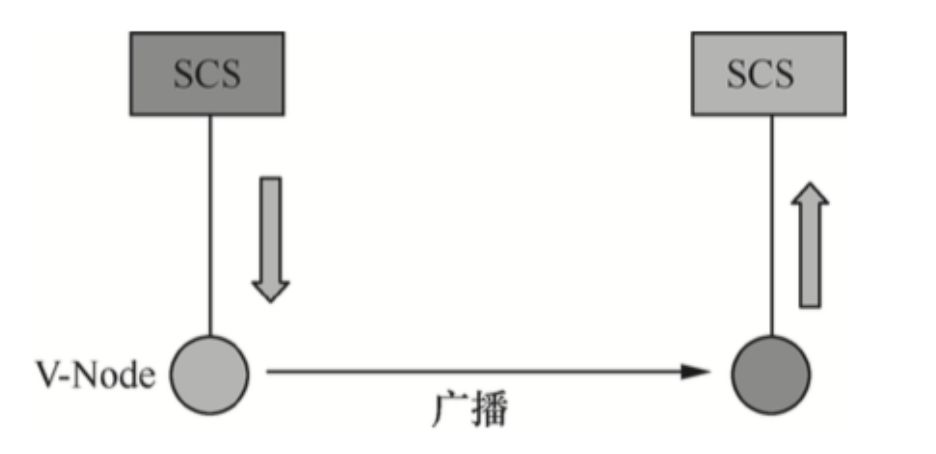
SCS节点之间的通信通过V-Node底层网络展现
SCS节点具有以下特点:
(1) 每个分片都有自己的存储,就是分片的区块链;
(2)SCS可以有不同于底层PoW的共识方式,如PoS、PBFT等;
(3) SCS的出块时间可以和底层不一致,比如可以采用较快的出块周期,进一步提高处理速度;
(4) SCS周期性的向底层同步状态结果,获得阶段性的全局一致性。
与以太坊等设想的分片方式不同,墨客分片采用合约驱动的模式,即一个合约对应一个系统分片。 合约创建时,会自动随机选择相应数量的SCS节点组成分片来处理合约。 这个合约的生命周期,从合约的创建到合约的终止,都是在分片中实现的。 当然,如果需要,你可以重新选择分片的SCS节点。
合约的执行尽量在SCS端执行,V-Node只处理支付交易和必要的合约调用。 如果你能有100个分片,那么处理合约的速度会提升100倍甚至更多。 同时,底层将处理大部分的支付交易。 这部分逻辑比较简单,可以完全降低支付交易的手续费,从而进一步提高处理能力。
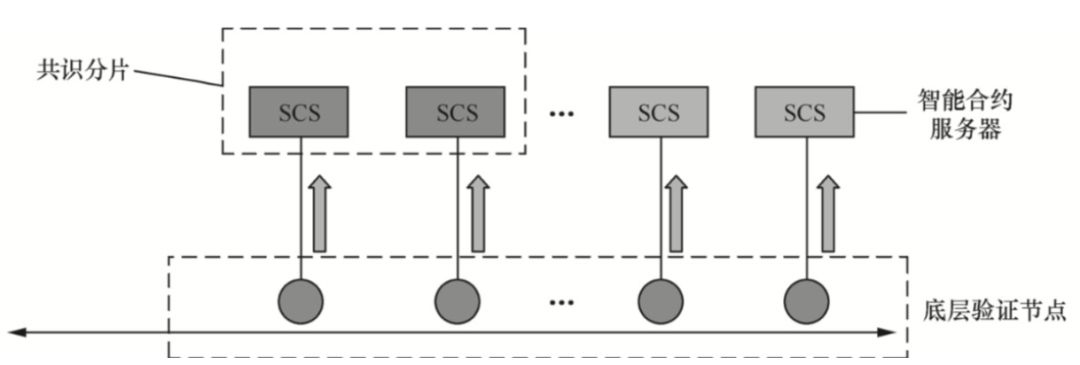
合约驱动的 Moac 分片
内存的价格更不是问题。 对于普通用户,因为SCS可以参与挖矿,所以不需要部署V-Node,只要有可信的V-Node可以连接即可。 这样,墨客系统将形成两级挖矿节点。
(1) 大量具有强大算力、高网络带宽、大存储容量的V-Nodes执行PoW并提供SCS接入服务,以维持网络所需的挖矿能力。 数量在几千到一万之间。
(2) 基于大量 CPU 的 SCS 用于处理合约执行。 由于子链的共识多样性,此类SCS节点甚至可以是手机等移动设备。 SCS 节点的数量可以是无限的。 在当前的架构下,数十万甚至数百万的 SCS 可以参与,而不会影响系统的性能。
Moac System将提供一些主要的共识协议分片实现,如PoS、PoA(Proof of Authority,权威证明)等,用户也可以将自己的共识协议实现为SCS的插件。 这形成了一个子链。
分层的
1.分片的瓶颈
比特币的共识机制是PoW,PoW作为底层共识机制会面临两个问题:第一,矿池带来的矿机算力是中心化的; 第二,矿机数量受矿机经济性限制,矿工数量有一个动态平衡的上限。 对于比特币、以太坊等公共系统,矿机规模越大,去中心化程度越高,系统的安全性也越高。 但是,当矿机数量(算力)超过10000台时,由于矿机的经济性(即挖矿收益与成本的平衡),矿机数量基本会有一个上限,会不是无限增长。
因此,对于采用分片技术的系统,系统的可扩展性会受到矿机规模的限制。 比如系统设置为每300台矿机分配一个分片,那么3000台矿机对应10个分片,10000台矿机对应33个分片。 如果应用进展顺利,用户数量快速增长,矿机数量将增加到30,000台。 假设每个芯片的处理速度可以达到1000TPS,那么系统的最终处理能力就是100000TPS,这是系统的上限。
2.分层技术原理
为了解决分片对系统处理速度造成的瓶颈,社区提出了分层结构的概念,即在系统架构上分离出不同的功能层,各自完成不同的功能。 例如,将系统分解为P2P网络层、区块链层、交易层、智能合约层、API层等各个功能层,如下图所示。 不同的功能层在系统中完成各自特定的功能。
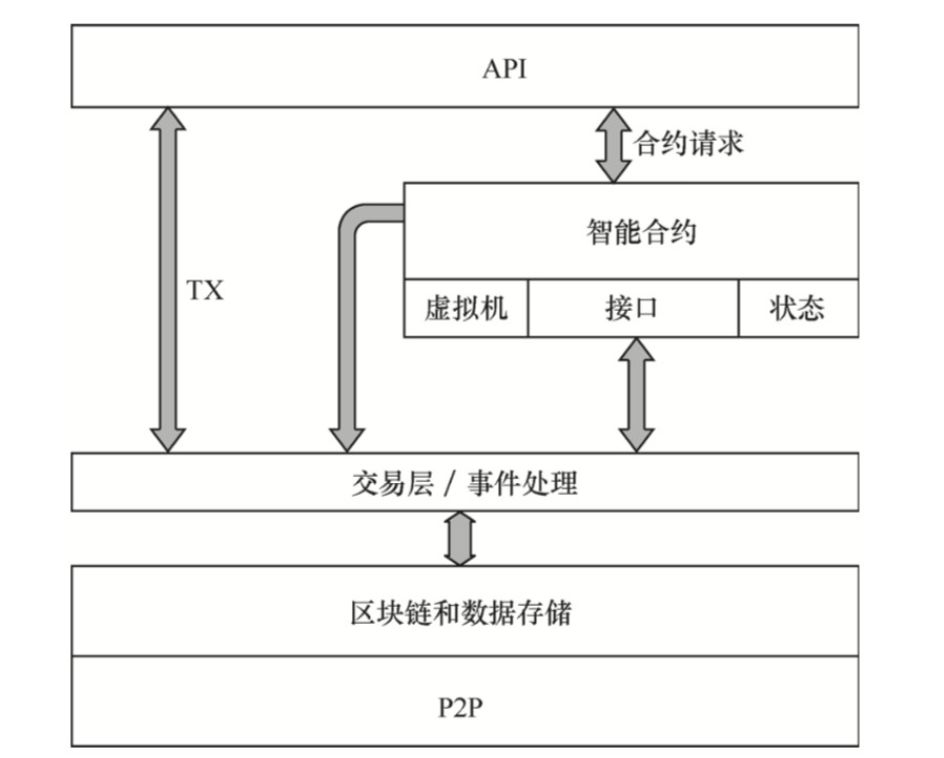
系统分层图
基于分层技术的智能合约层挖矿,如星际存储系统(IPFS)挖矿或物联网(IoT)挖矿,可以通过智能合约的建立来支付矿工费。 这跳出了矿机经济学的局限,成为谁设立(智能合约)谁付费的原则。 这样的转变使得 SCS 节点的数量在理论上可以无限增长。 因此,在系统上线之初,随着大量智能合约的上线,SCS节点数量可能会超过10万,甚至上百万。
智能合约层的运行需要考虑应用场景的多样性。 应用场景的多样性可以类比高速公路的情况。 高速公路不仅要保证汽车在上面行驶的速度,还需要保证不同类型的汽车都能通行,比如卡车、越野车、家用车,甚至摩托车。 对应智能合约层,项目方需要能够自由选择智能合约所需的节点数量、不同的共识机制、出块速度和主网刷新时间等。换句话说,系统只需要提供一个基础框架,然后让项目方根据不同的应用场景灵活调整功能。
3. Moac的分层技术
Moac的分层技术就是基于上述分层概念提出的。 同时,为了能够在大型网络中部署分布式系统,吸引更多参与者比特币系统发病数量,并保持高吞吐量和低延迟,Moac 提出了分层共识栈技术方案。 其具体实现机制如下。
a) 采用层级结构
Moac系统分别处理简单的原生交易(Balance Transfer)和智能合约的执行,底层以PoW形式处理所有原生交易和全局合约,解决全局一致性和双花问题。 系统智能合约部署在上层,通过特定的共识机制处理,采用分片技术,使系统TPS提升100倍。
b) 作为微链的智能合约 (SAAM)
每个部署的智能合约实际上是一个子链。 它可以选择需要的验证节点(挖矿节点),选择适合自己的共识机制,拥有自己的区块链来保存状态。 子链采用周期刷新机制,将自身状态的哈希值写入底层区块链,实现最终共识。
c) 双层挖矿机制
PoW底层采用与以太坊相同的挖矿方式,此类挖矿节点数量从几千到几万不等。 上层挖矿采用DApp支付挖矿费的方式,按使用矿机数量和单位产量支付。 此类挖矿节点的数量可以从数十万到数百万不等。 每个矿工随机参与到一条子链中,提供服务并获得收益。
在这样的配置环境下,上层挖矿不再是一个负反馈的过程。 每个矿工产生一个区块的收益是相对固定的。 如果部署了大量应用,则需要大量矿工为这些应用提供服务。 大量矿工的加入,一方面扩大了生态的规模,另一方面提升了系统的服务能力,从而吸引更多的应用部署到平台上。
由于文章篇幅,关于侧链、子链和跨链,请看今天其他文章(三、四)

本期话题:谈谈你目前对区块链性能优化方案(任意方向)的理解(50字以上)。
请文末畅所欲言,营长将从选定的留言用户中抽取5位幸运读者,免费赠送一本书!
截止日期为4月2日(下周二)中午12:00!